云原生安全Kubernetes基础篇
TL;DR
本文记录了我在学习Kubernetes及云原生架构安全中的笔记,大部分内容均来自Kubernetes官方文档,作为一个初学者非常推荐阅读官方文档来系统地学习Kubernetes,而本文的内容只是总结了部分和安全相关的知识点。
Kubernetes对象
(引用自:资源对象与基本概念解析 · Kubernetes Handbook - Kubernetes 中文指南/云原生应用架构实践手册 · Jimmy Song)
| 类别 | 名称 |
|---|---|
| 资源对象 | Pod、ReplicaSet、ReplicationController、Deployment、StatefulSet、DaemonSet、Job、CronJob、HorizontalPodAutoscaling、Node、Namespace、Service、Ingress、Label、CustomResourceDefinition |
| 存储对象 | Volume、PersistentVolume、Secret、ConfigMap |
| 策略对象 | SecurityContext、ResourceQuota、LimitRange |
| 身份对象 | ServiceAccount、Role、ClusterRole |
可使用create、get、describe、delete、edit、replace等操纵上述对象(有的对象只支持部分操作或拥有其他对象没有的操作方法),较为通用的参数(-n 指定命名空间,-o 指定输出格式),对象的操作都是在默认命名空间下执行的,可指定--all-namespaces参数显示指定所有的命名空间。
部分对象示例:
1 | 查看所有节点 |

1 | 查看所有Pod |
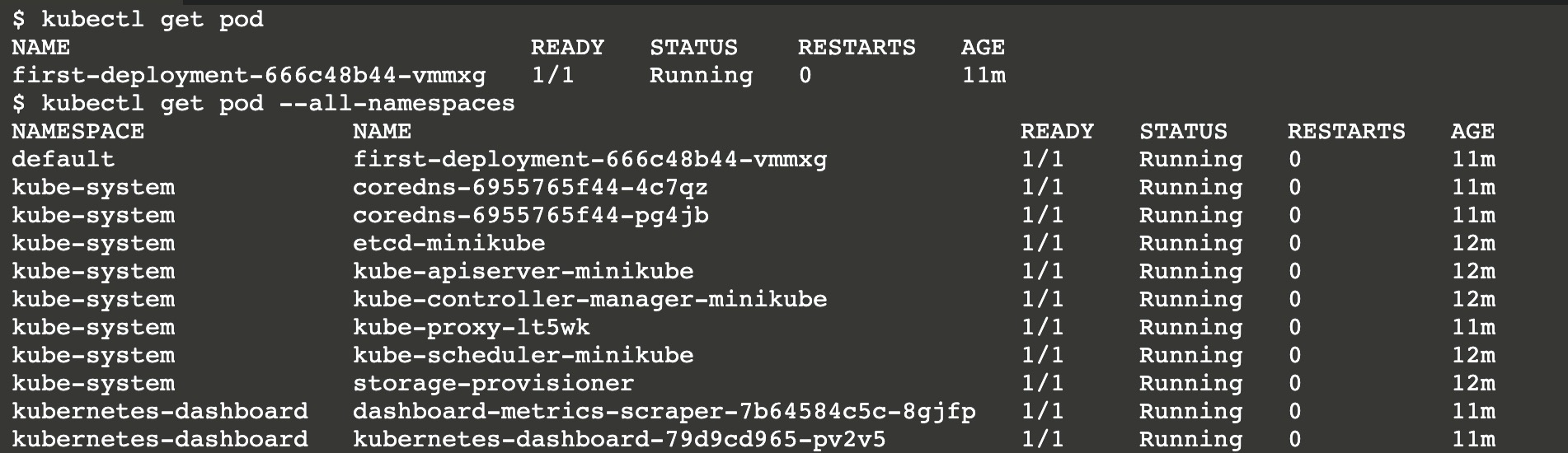
1 | 查看暴露的服务 |
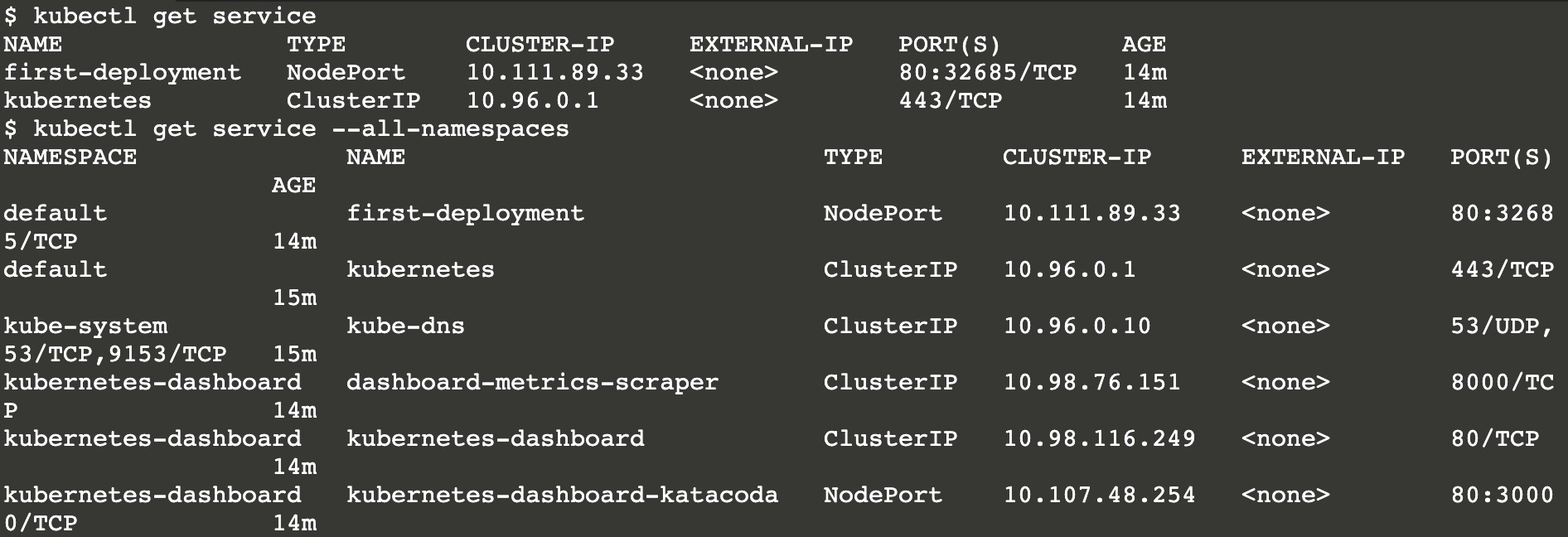
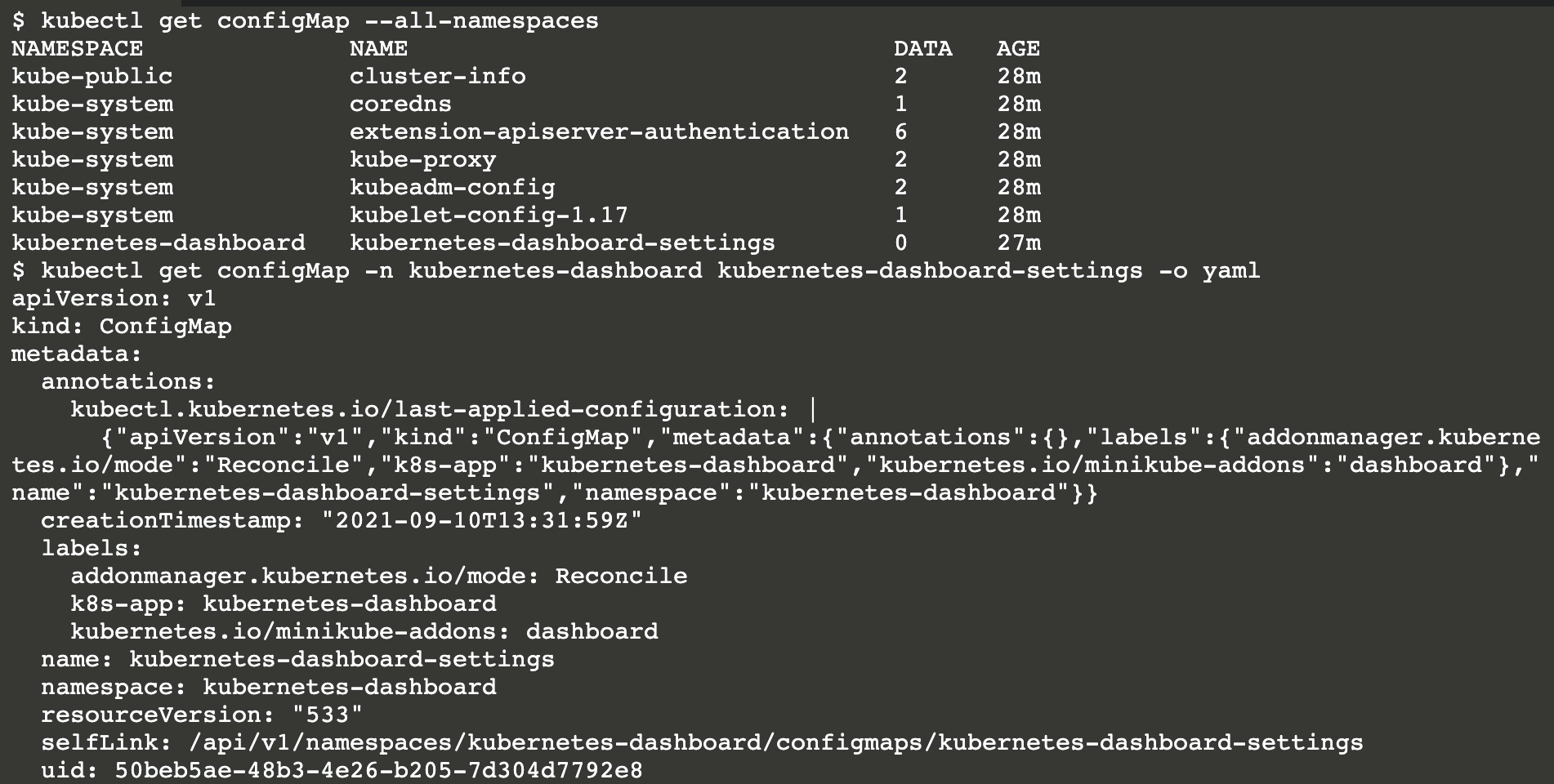
1 | 查看服务账户, 下述的命令指定了命名空间以及输出格式为yaml |
输出的资源清单中包含了该帐号所属的命名空间,元数据中包含了一些注释信息,以及对应的secret对象。
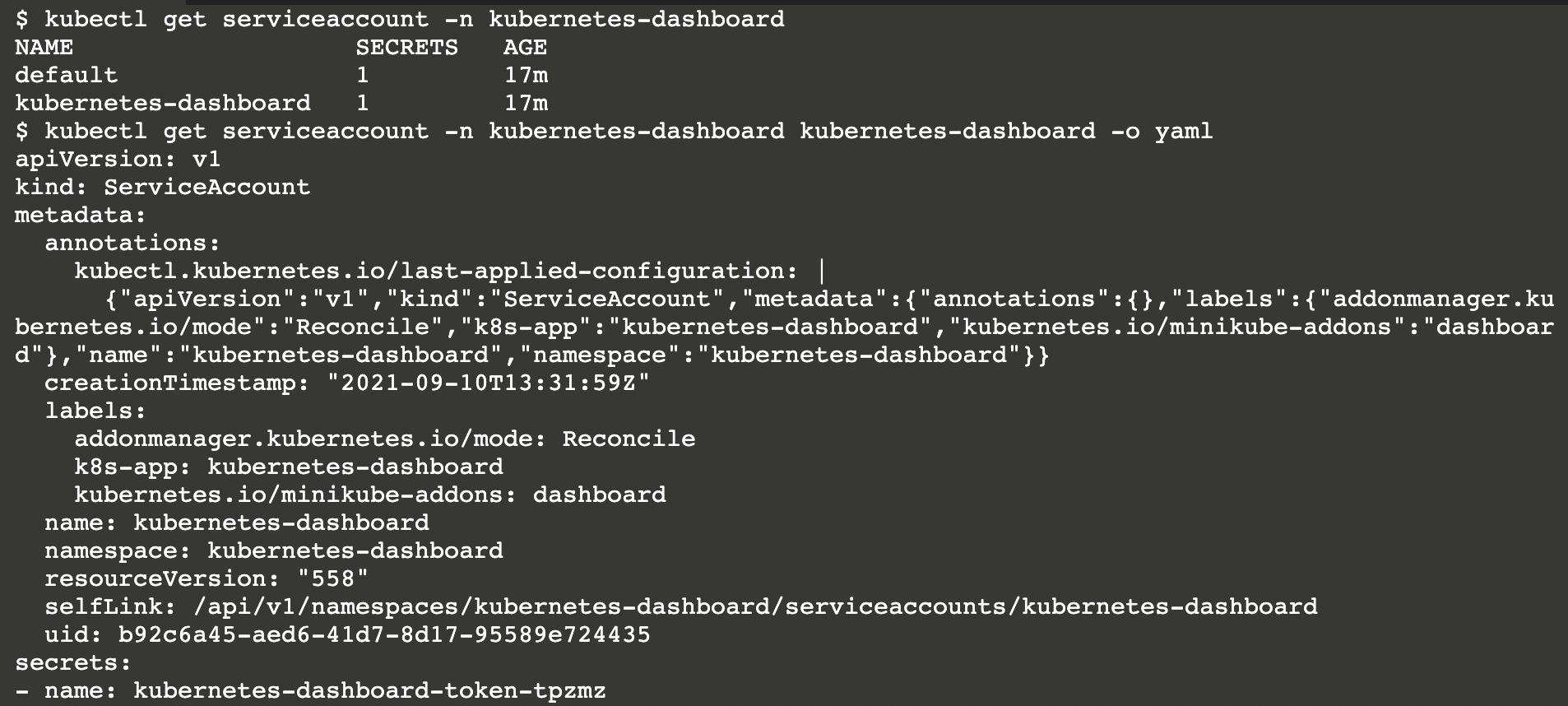
1 | secret对象一般存储K8s集群中的证书、token等 |
该token可用于Kubernetes API认证,Kubernetes默认使用RBAC鉴权(当使用kubectl命令时其实是底层通过证书认证的方式调用Kubernetes API)。
1 | ConfigMap对象一般存储应用配置信息, 在创建Pod时或在容器中可以引用这些配置信息 |
RBAC鉴权
基于角色(Role)的访问控制(RBAC)是一种基于组织中用户的角色来调节控制对 计算机或网络资源的访问的方法。
RBAC API 声明了四种 Kubernetes 对象:Role、ClusterRole、RoleBinding 和 ClusterRoleBinding。你可以像使用其他 Kubernetes 对象一样, 通过类似kubectl这类工具 描述对象, 或修补对象。
先说Role和ClusterRole的区别,Role用于在某个命名空间中设置访问权限,而ClusterRole用于设置集群范围内的访问权限(跨命名空间及非资源端点),简单理解只是作用域不同而已,ClusterRole作用域更加广泛。
再来说说RoleBinding和ClusterBinding,其实跟上面的描述差异不大,下面是官方文档的描述:
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。 它包含若干 主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用。 RoleBinding 在指定的名字空间中执行授权,而 ClusterRoleBinding 在集群范围执行授权。
角色绑定可以引用同一命名空间下的任何角色,或者角色绑定可以引用集群角色(ClusterRole),这样一来能够将集群角色(ClusterRole)绑定到RoleBinding所在的命名空间(其作用域就不再是所有命名空间了)。如果需要将某个集群角色(CLusterRole)绑定到所有命名空间,则需要使用ClusterBinding。
Role示例
1 | # pod-reader角色只拥有pod的读访问权限 |
RoleBinding示例
下面的例子中的 RoleBinding 将 “pod-reader” Role 授予在 “default” 名字空间中的用户 “jane”。 这样,用户 “jane” 就具有了读取 “default” 名字空间中 pods 的权限。
1 | apiVersion: rbac.authorization.k8s.io/v1 |
ClusterRole
下面是一个 ClusterRole 的示例,可用来为任一特定名字空间中的 Secret 授予读访问权限, 或者跨名字空间的访问权限(取决于该角色是如何绑定的):
1 | apiVersion: rbac.authorization.k8s.io/v1 |
ClusterBinding
要跨整个集群完成访问权限的授予,你可以使用一个 ClusterRoleBinding。 下面的 ClusterRoleBinding 允许 “manager” 组内的所有用户访问任何名字空间中的 Secrets。
1 | apiVersion: rbac.authorization.k8s.io/v1 |
配置不当导致集群接管
当使用K8s提供的Dashboard(Web面板)来管理集群时,错误的配置将导致集群被接管,在K8s Master中可以使用如下命令安装Kubernetes官方提供的Dashboard。
1 | kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml |
在官方提供的Yaml文件中可以看到其内置了一些默认帐号,而当使用K8s面板时开启enable-skip-login将会使用默认的kubernetes-dashboard帐号登陆。(面板通过服务暴露的方式映射为8443端口,如下图41-42行所示)
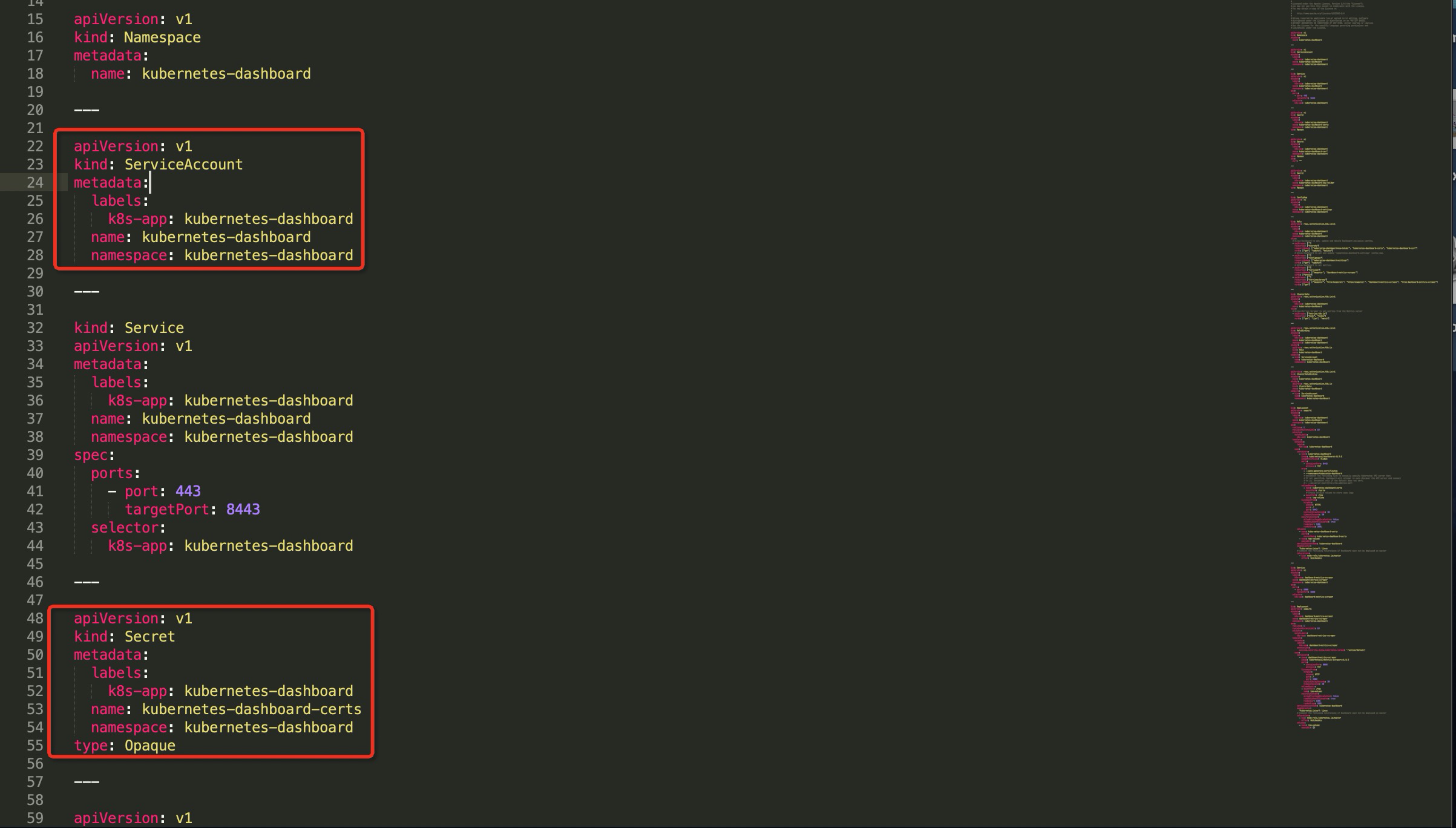
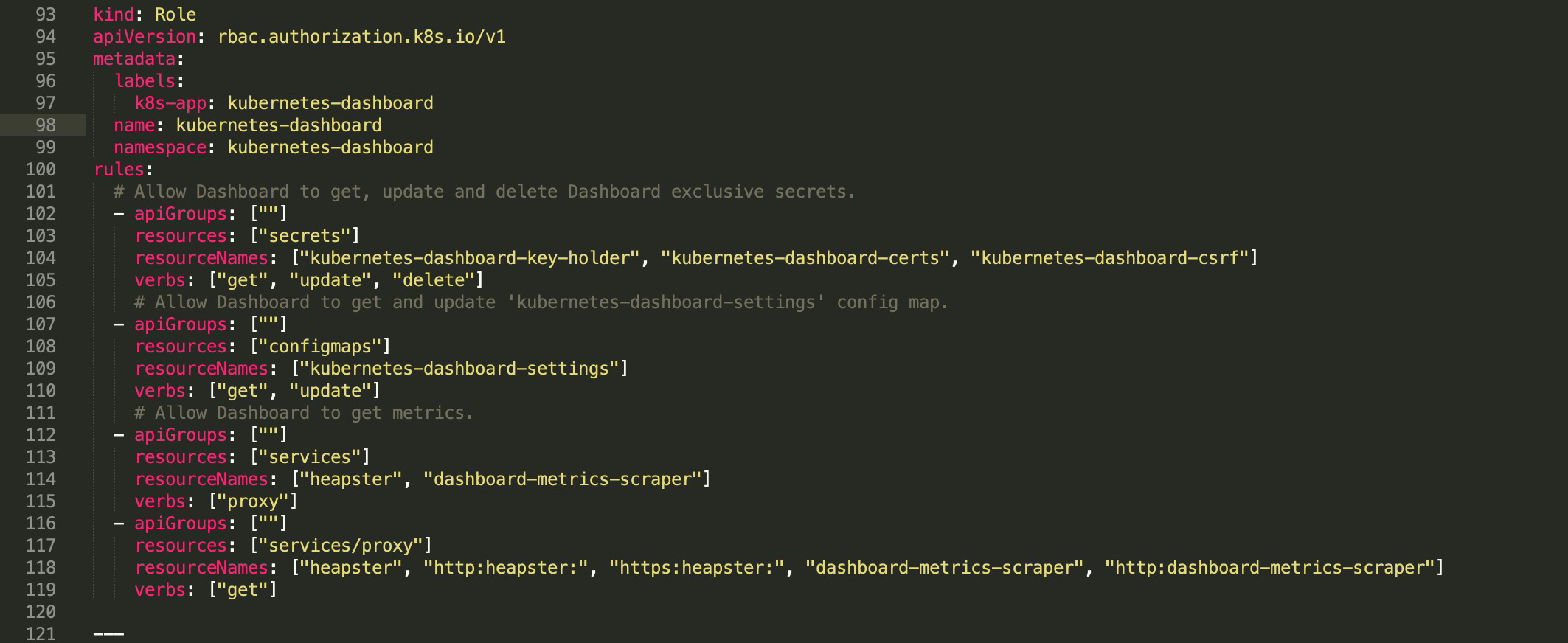
而官方提供的示例文件中kubernetes-dashboard将拥有以下权限。
案例演示
在学习Kubernetes的过程中总避免不了复杂的环境搭建,为了避免麻烦我将使用katacoda提供的在线演示环境,在其第一节环境中你就能够体验部署Kubernetes Dashboard的过程,当你部署完毕时访问Dashboard的url,你只需要点击Skip就能够登陆到Dashboard中。
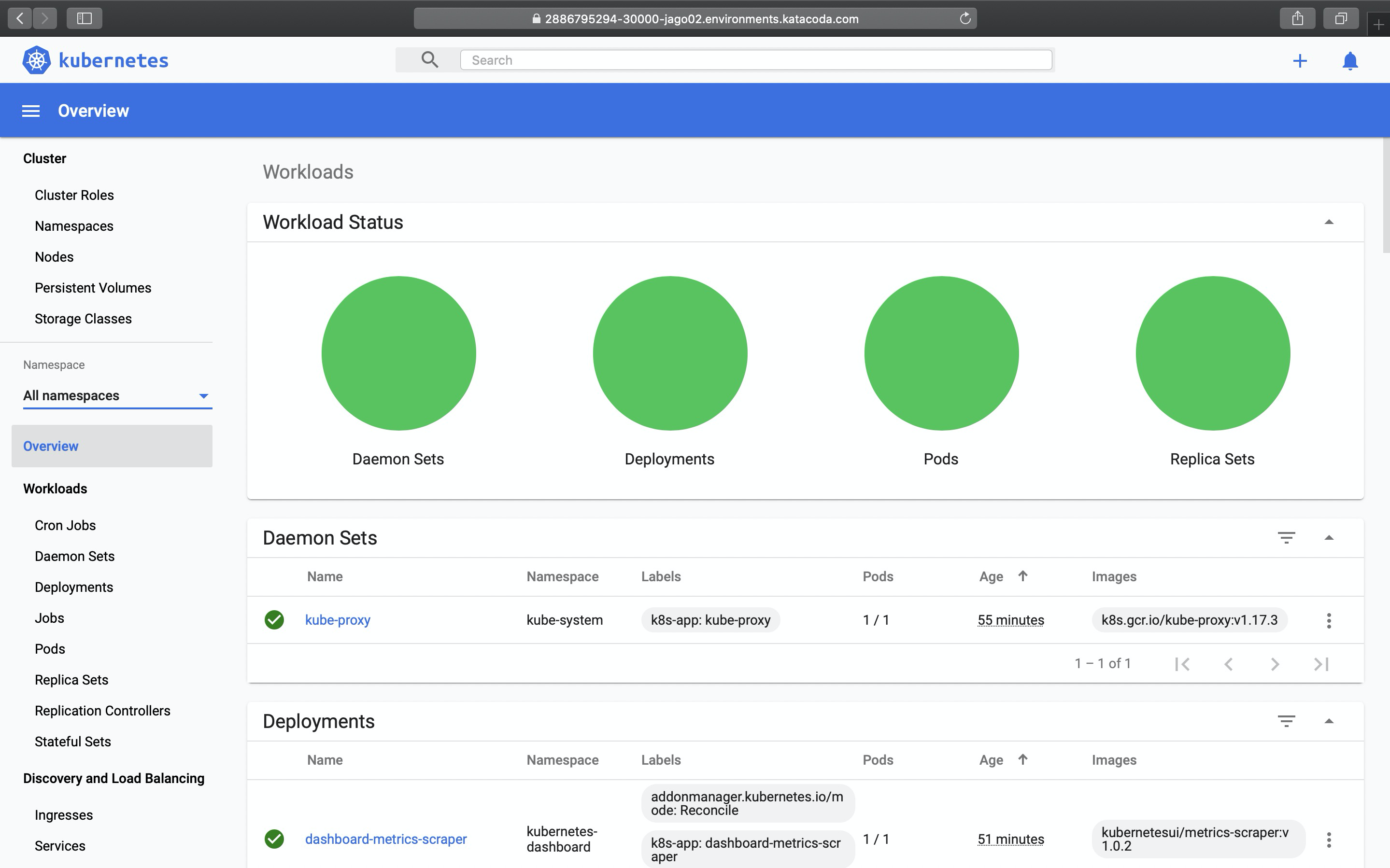
并且拥有所有权限。
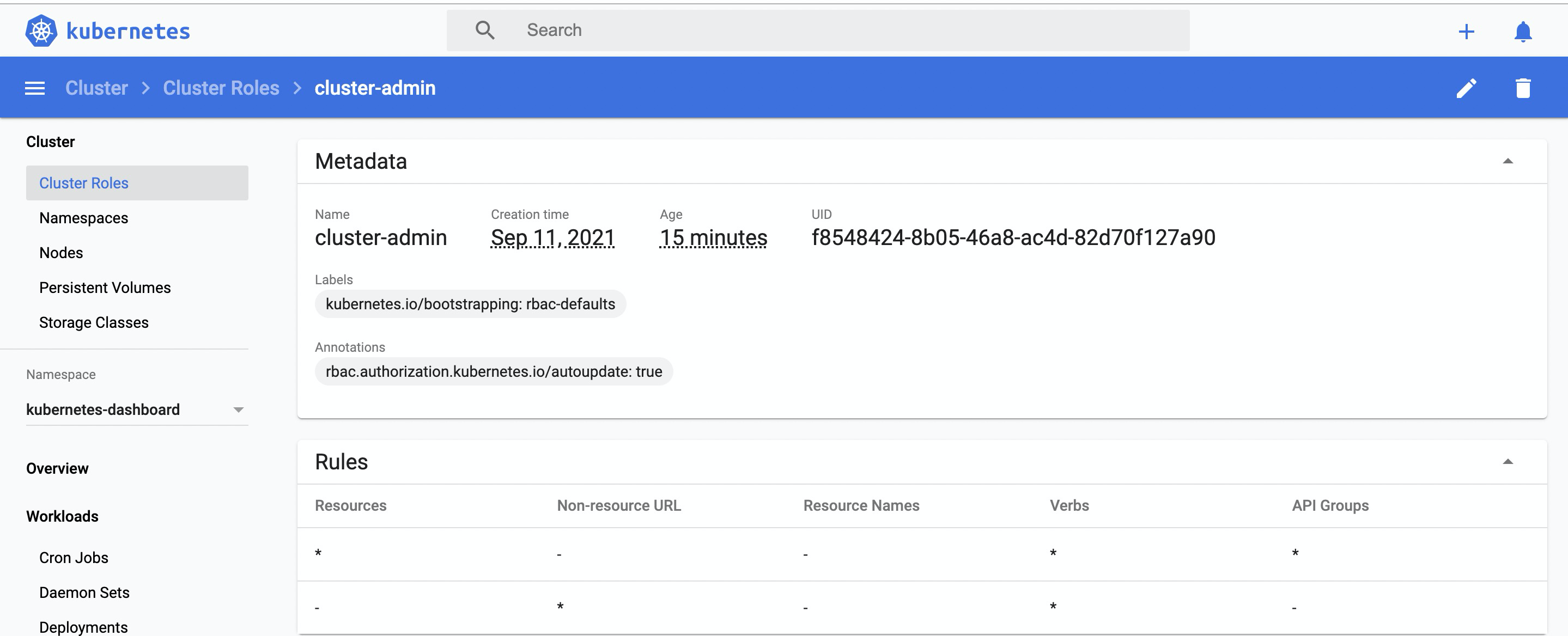
而其中的原因则来自于创建Dashboard Pod时开启的enable-skip-login以及授予默认账户的管理员权限。
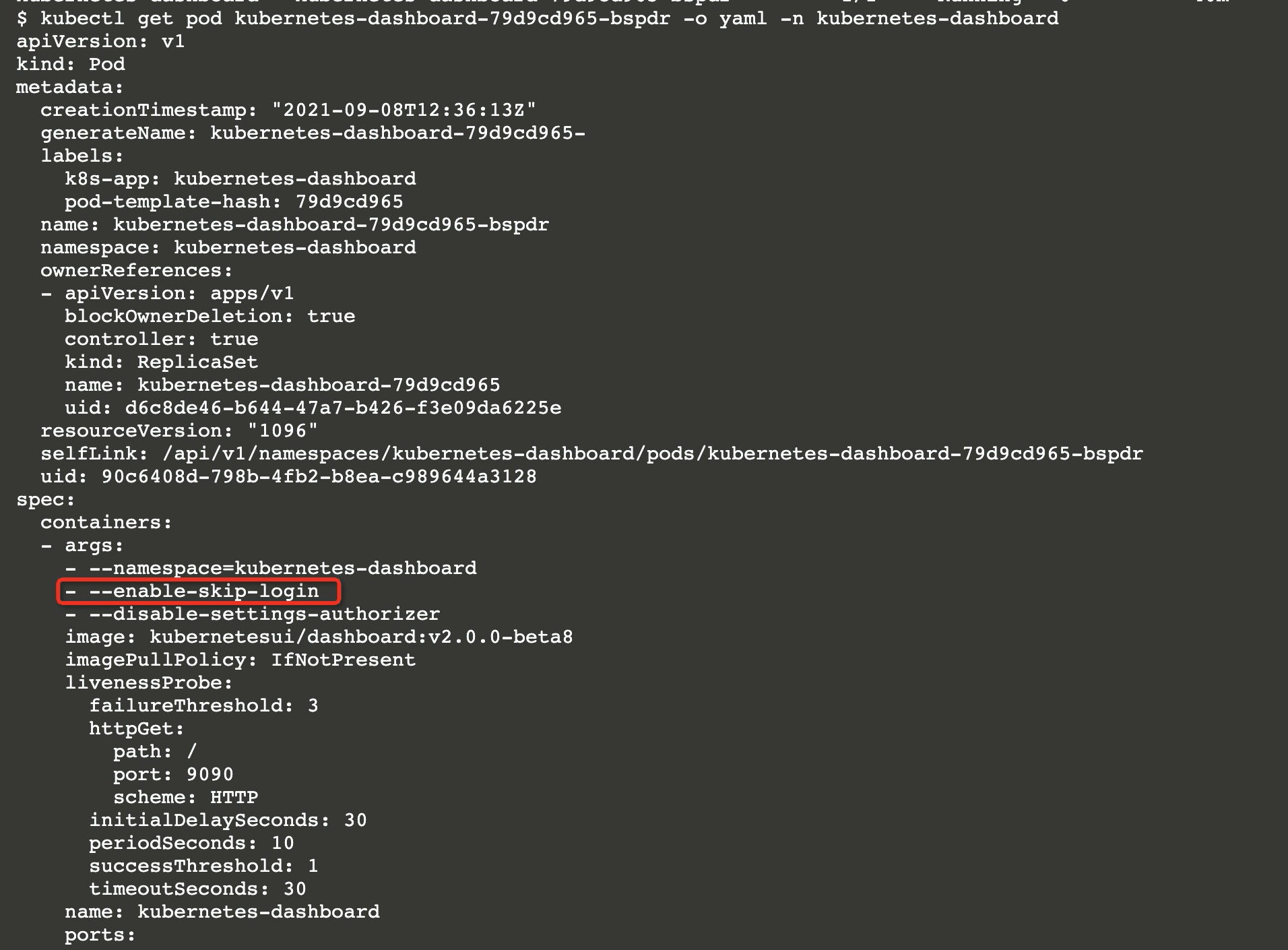
如何查找该Pod文件?只需要执行如下命令。
1 | 该命令将显示所有命名空间下的Pod,你只需要找到kubernetes-dashboard命名空间下以kubernetes-dashboard命名的Pod即可 |
查看默认的kubernetes-dashboard的账户权限可以通过查询(内置账户都是ServiceAccount,由K8s集群管理)ServiceAccount、ClusterRoleBinding、RoleBinding等资源对象。
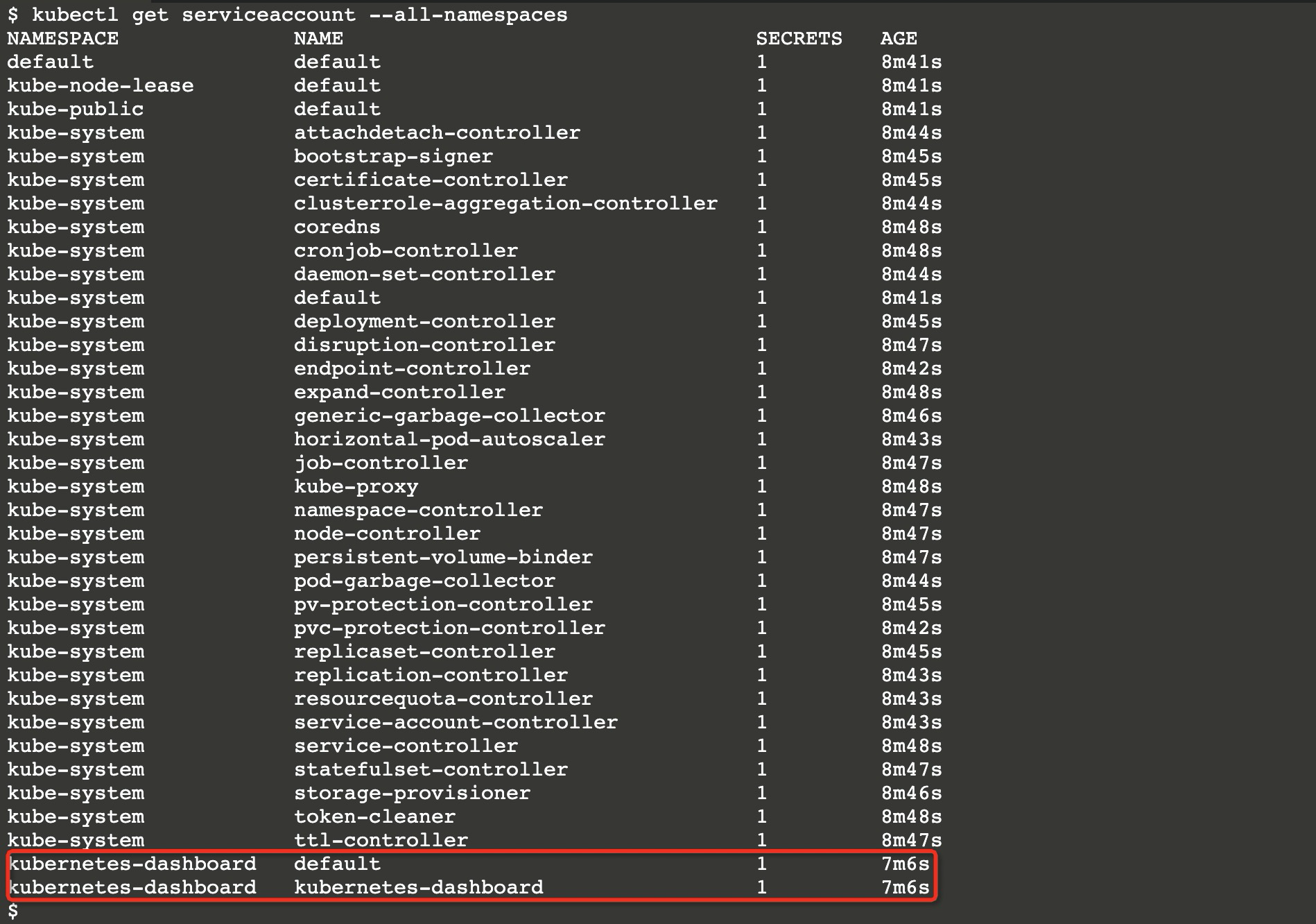
引用的类型为集群角色,该角色名为cluster-admin(Kubernetes内置的集群超管角色)。
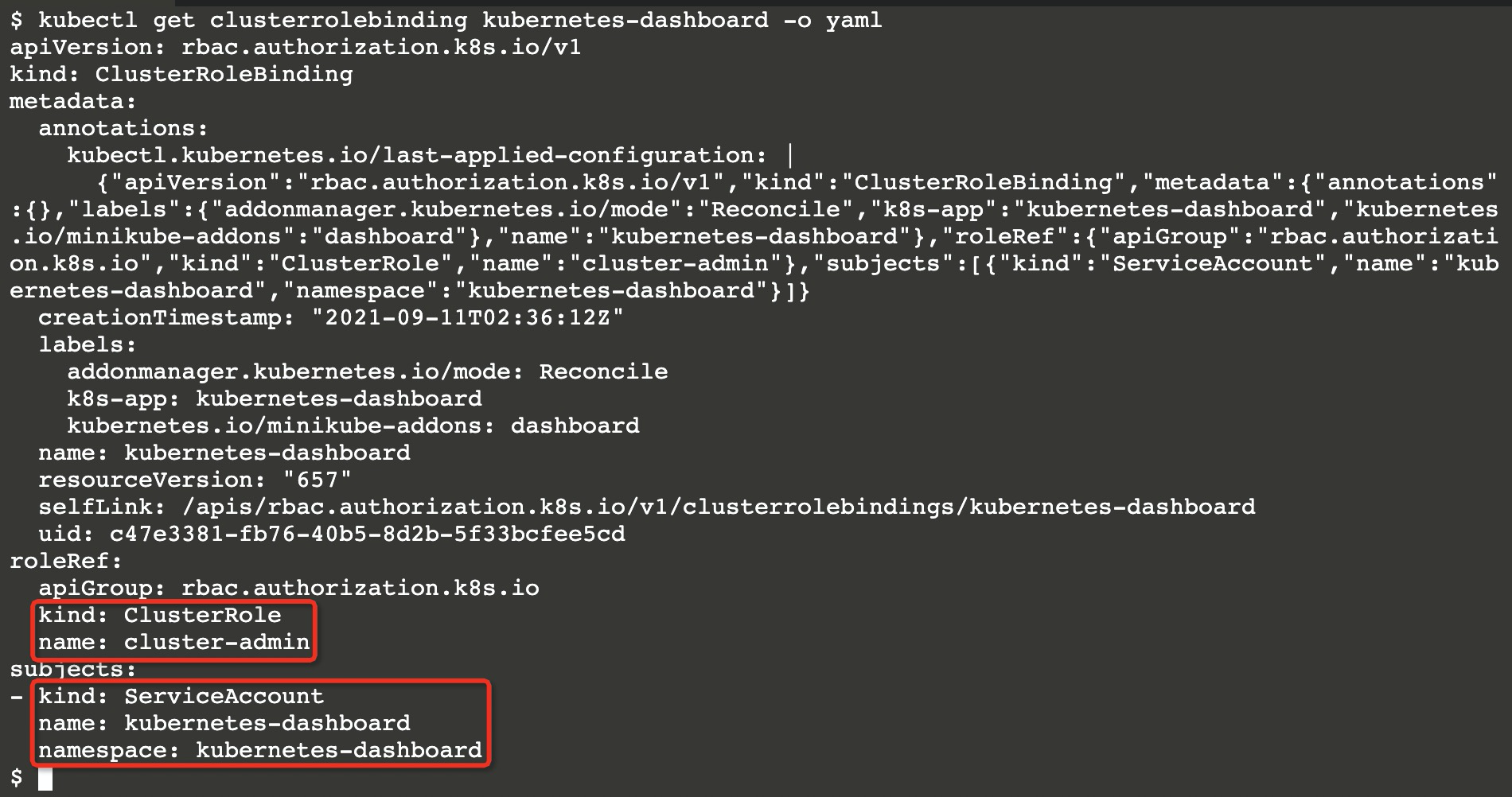
拥有所有对象的操纵权限。
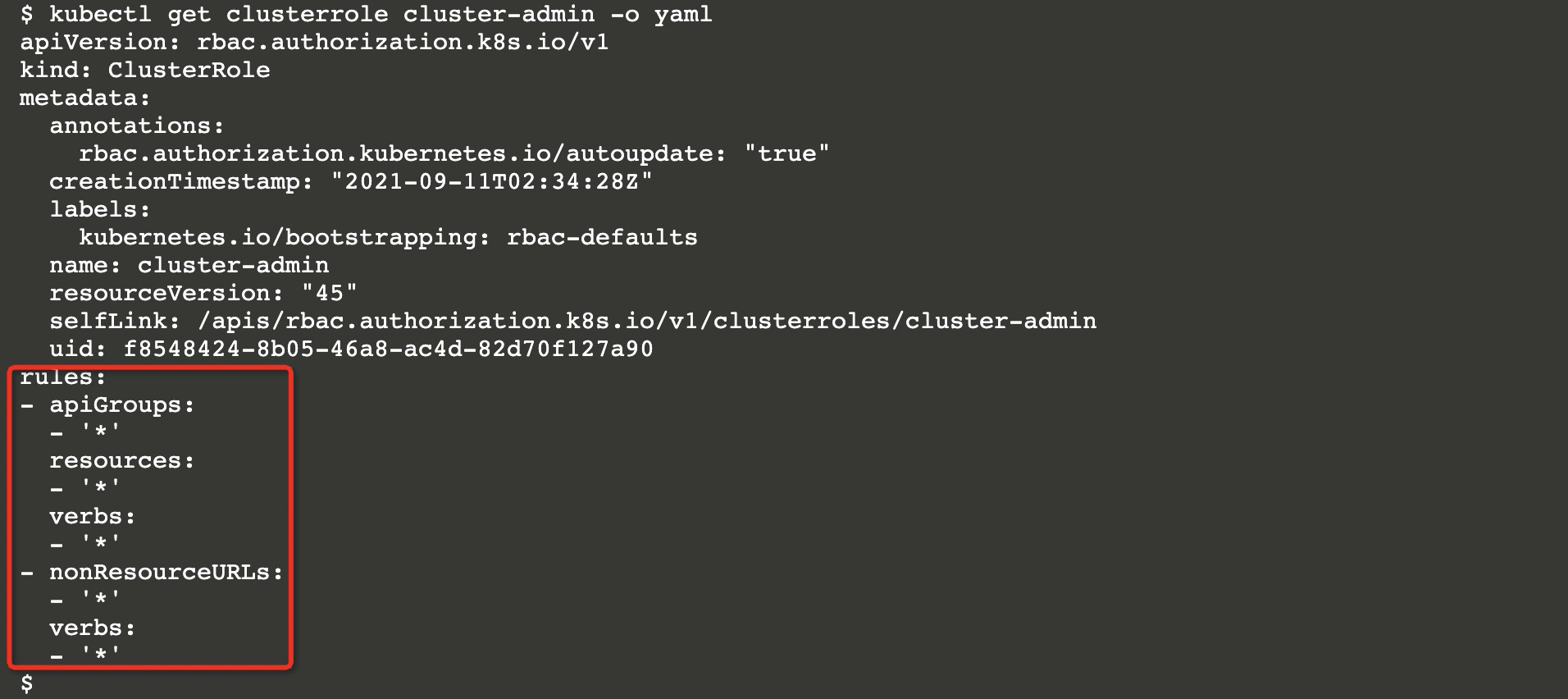
Node逃逸
当通过Kubernetes Dashboard或其他攻击方式能够创建Pod或控制某个容器时,下一步的横向渗透将会是思考如何逃逸至(Node)节点中。在容器中的节点逃逸与平常的Docker逃逸并无差异(逃逸宿主机),而当获取到Kubernetes Dashboard权限时逃逸将变得更加轻松不过了,你只需要创建一个Pod,在容器中挂载宿主机的根目录以写入SSH公钥/定时任务等方式即可实现逃逸,下面的资源清单将演示这一过程。
1 | apiVersion: v1 # 版本 |
上述的Pod创建完毕运行后将把宿主机的根目录挂载到自己的/tmp/rr目录下,如果你想指定逃逸某个指定的Node或Master时,将会在下一节Pod的(亲和性、反亲和性)与(污点、容忍度)中详细说明。
亲和性与反亲和性
如果你的Kubernetes集群拥有多个Node(节点),你可能需要在创建Pod时指定由哪个Node调度该Pod。比较简单的方式是你可以通过nodeName属性和nodeSelector属性来指定Node,尝试创建下述的资源清单并运行该Pod。
1 | apiVersion: v1 |
如果node01节点满足Pod的资源需求,则节点会运行该Pod。而nodeSelector与上述功能相同,也能够将Pod分配给指定的节点调度,其通过匹配标签(Label)的形式分配。
1 | 该命令为node01节点添加一个标签 |

1 | apiVersion: v1 |
节点亲和性
亲和性相比nodeSelecetor的表现而言更加灵活,亲和性支持In、NotIn、Exists、DoesNotExists、Gt、Lt等操作符。其类型可区分为requiredDuringSchedulingIgnoredDuringExecution与preferredDuringSchedulingIgnoredDuringExecution,前者为必须满足的要求,而后者则无需强制满足。
下面是一个使用节点亲和性的Pod示例:
1 | apiVersion: v1 |
此节点亲和性表示该Pod只能被具备kubernetes.io/e2e-az-name标签且值为e2e-az1或e2e-az2,在满足该条件的情况下还将在具备another-node-label-key标签且值为another-node-label-value节点上优先调度。
如果同时指定了nodeSelector和nodeAffinity的话则两者都必须满足条件才会被调度。
如果同时指定了多个nodeSelectorTerms的话则只需要满足其中一个即可具备调度条件。
如果同时指定了多个matchExpressions则必须所有匹配表达式都满足才能够调度。
preferredDuringSchedulingIgnoredDuringExecution中的weight字段值的 范围是 1-100。 对于每个符合所有调度要求(资源请求、RequiredDuringScheduling 亲和性表达式等) 的节点,调度器将遍历该字段的元素来计算总和,并且如果节点匹配对应的 MatchExpressions,则添加“权重”到总和。 然后将这个评分与该节点的其他优先级函数的评分进行组合。 总分最高的节点是最优选的。「kubernetes.io」
Pod间亲和性与反亲和性
Pod 间亲和性与反亲和性使你可以 基于已经在节点上运行的 Pod 的标签 来约束 Pod 可以调度到的节点,而不是基于节点上的标签。 规则的格式为“如果 X 节点上已经运行了一个或多个 满足规则 Y 的 Pod, 则这个 Pod 应该(或者在反亲和性的情况下不应该)运行在 X 节点”。 Y 表示一个具有可选的关联命令空间列表的 LabelSelector; 与节点不同,因为 Pod 是命名空间限定的(因此 Pod 上的标签也是命名空间限定的), 因此作用于 Pod 标签的标签选择算符必须指定选择算符应用在哪个命名空间。 从概念上讲,X 是一个拓扑域,如节点、机架、云供应商可用区、云供应商地理区域等。 你可以使用
topologyKey来表示它,topologyKey是节点标签的键以便系统 用来表示这样的拓扑域。
1 | apiVersion: v1 |
在这个Pod的亲和性规则中定义了一条亲和性规则和反亲和性规则,在该示例中亲和性的规则要求满足security标签且值为S1,而反亲和性规则如果security标签为S2则Pod不应该被调度到此节点上,(topology.kubernetes.io/zone是内置的标签,表示一个可用区),更多内置标签、注解、污点,请查看完整文档:常见的标签、注解和污点 | Kubernetes。
下述例子将演示在拥有三个节点的Kubernetes集群上,如何使用Pod亲和性与反亲和性让每个节点上运行一组应用(Redis + Web Server),而不会在一个节点上重复运行。(这需要用到内置标签kubernetes.io/hostname,标签值为主机名生成)。
1 | apiVersion: apps/v1 |
web-server的Deployment控制器配置了Pod亲和性与反亲和性,这将通知调度器将它的所有副本与具有app=store选择器标签的Pod放置在一起。
1 | apiVersion: apps/v1 |
最终的运行结果为如下所示:
| node01 | node02 | node03 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
污点与容忍度
节点亲和性是Pod的一种属性,它使Pod被吸引到一类特定的节点上。而污点(Taint)恰恰相反,它能够使节点排斥某一类Pod。
容忍度是应用在Pod上的属性,它与污点相互配合,可以避免Pod被分配到不具备污点的节点上。每个节点都应用一个或多个污点。
1 | 为节点添加污点 |

这是一个使用了容忍度的Pod,当创建时它只会被node01节点调度,因为其他节点不具备该污点。
1 | apiVersion: v1 |
operator属性的默认值是Equal,这表示键的值必须与value属性的值一致。而如果operator是Exists的话则容忍度不能指定value,而污点上的任意值都能够匹配该污点(前提是key匹配)。
如果一个容忍度的
key为空且operator为Exists,则表示这个容忍度与任意的key、value和effect都能够匹配,即这个容忍度能容忍任意污点(taint)。如果污点未指定
effect且容忍度中effect属性为空,则只需键匹配即可(eg: key1=value1)。
上述例子中的key1的effect为NoSchedule,还可以使用另一个值PerferNoSchedule,其表示尽量避免将Pod调度到存在不能容忍污点的节点上。以及NoExecute值,在不能容忍污点的节点上该Pod会被驱逐(已运行的情况下)。
示例
使用污点和容忍度能够使Pod灵活的避开某些节点或者将某些Pod从节点上驱逐。例如Kubernetes Master拥有默认的污点(这也是为什么Master上不会运行Pod的部分原因)。
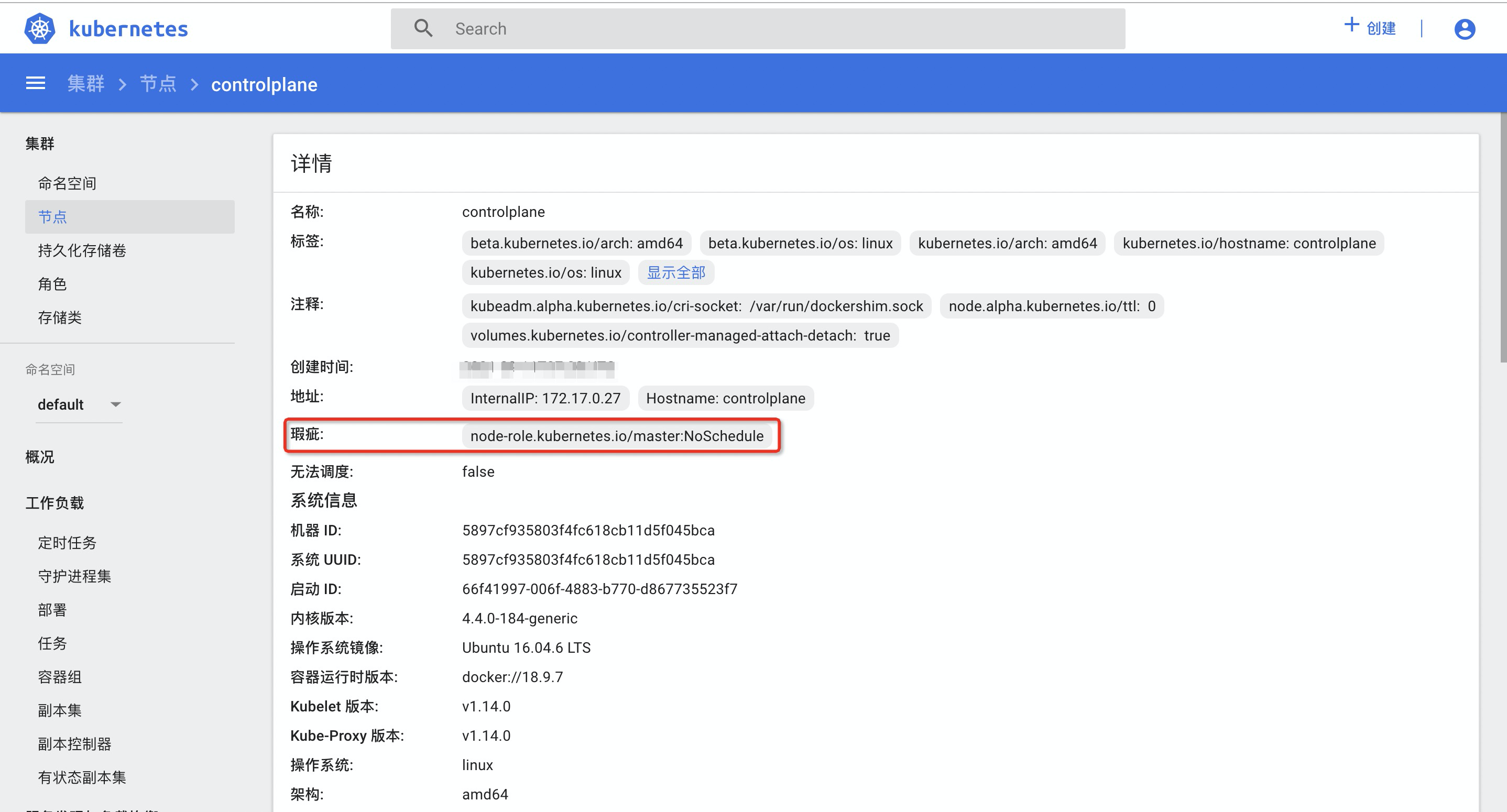
因此可以通过创建一个具有node-role.kubernetes.io/master:NoSchedule的容忍度让Pod被Kubernetes Master所调度。
1 | apiVersion: v1 |
在上述的Pod中如果将宿主机的根目录挂载到容器中(利用volumes与volumeMounts)即可逃逸至Kubernetes Master中接管集群。
apiserver
未授权
Kubernetes API服务器在2个端口上提供服务,分别为8080与6443(安全端口),安全端口使用TLS加密,默认IP是第一个非本地网络接口,安全端口的请求需经身份认证和鉴权组件处理,请求必须经准入控制模块处理。
而8080端口(localhost 非安全端口)默认情况下用于测试,不使用TLS加密。因此如果暴露该端口则有可能导致未经授权的请求调用API Server。
使用kubectl可以指定IP和端口调用存在未授权漏洞的API Server。
1 | kubectl -s ip:port get nodes |
证书认证
在Kubernetes Master中使用 kubectl 命令行工具来管理Kubernetes集群,kubectl 在 $HOME/.kube目录中查找一个 config 的配置文件(默认情况)。你也可以使用 --kubeconfig 参数来指定其他配置文件,配置文件中包含了证书文件的地址,实际上也可以将证书内容硬编码在配置文件中(效果都是一样的)。
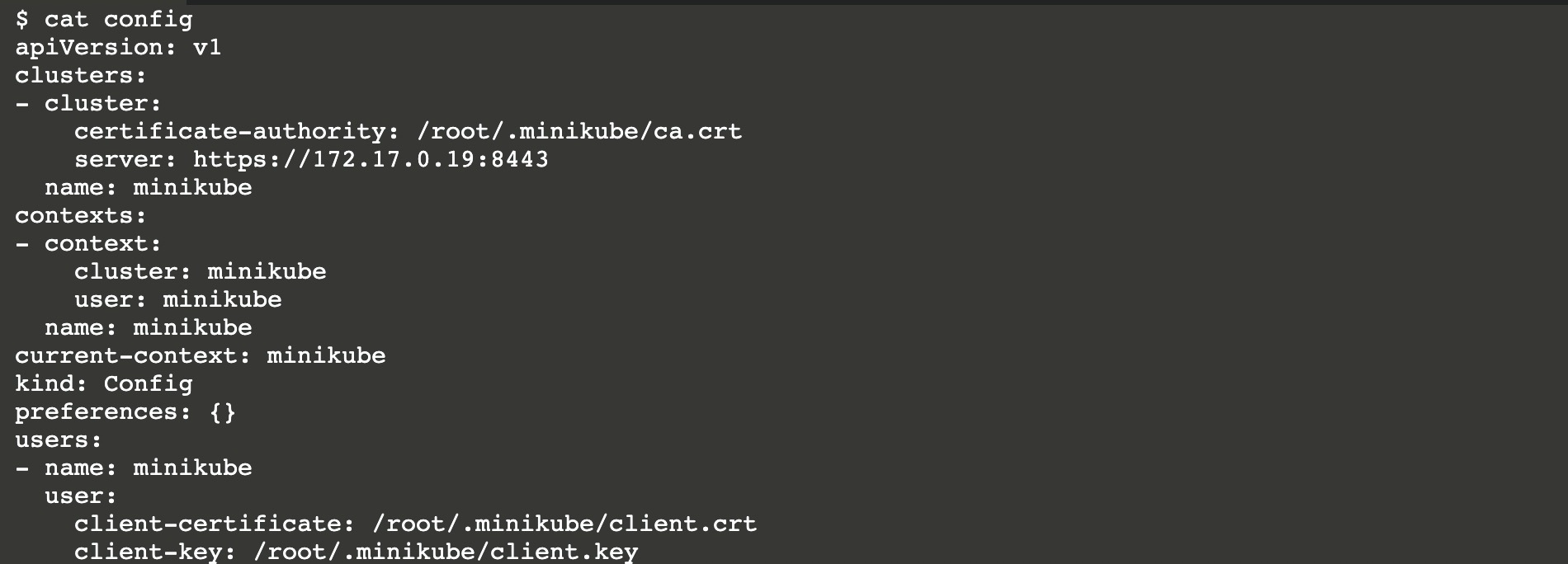
Kubelet
Kubelet运行在每个Node节点上,其基于 PodSpec 工作。Kubelet通过接收api server提供的一组 PodSpec ,并确保 PodSpec 中的容器处于运行状态且运行状况良好,简言之,Kubelet负责管理容器的生命周期。
Kubelet服务默认监听10250与10255端口,前者为安全端口并使用HTTP/S,而后者则为无需身份验证/鉴权的只读端口,Kubelet的配置文件默认位于 /var/lib/kubelet/config.yaml。
如果Kubelet配置了允许匿名访问的话,则会以 system:anonymous 用户名和system:unauthenticated组的身份请求API。(下图是关闭状态)
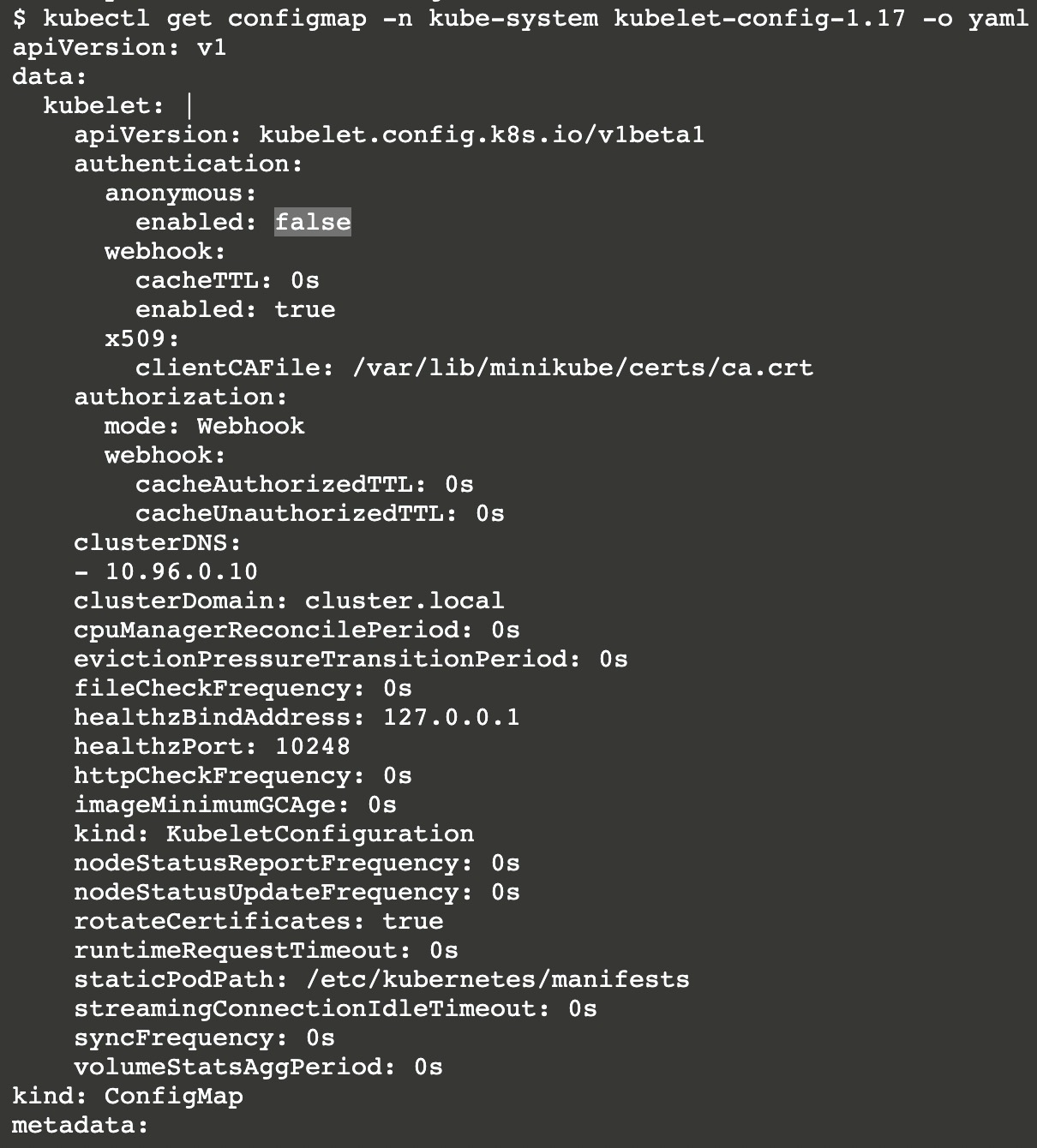
Kubeletctl
Kubeletctl是基于Kubelet API实现的Cli工具,通过其可以快速实现对Kubelet的攻击。
1 | 命令示例 |
总结
实际上在真正的云原声环境中渗透远不止本文所提及的内容,在云环境的渗透场景中错综复杂。但攻击者视角所关注的应远不止于容器应用中的提权(指容器逃逸),信息收集同样十分重要。
- 在主机中全局搜索
config配置文件(find / -iname “*config*“ | grep -RiE “server:\s*https?://.*?:8443”)。 - 使用CDK工具进行横向渗透及信息收集
References
Learn Kubernetes using Interactive Browser-Based Labs | Katacoda